Prerequisites
- Products: Liquid UI WS, Liquid UI Server or Local DLL, Client Software
- Commands: inputfield(), pushbutton(), del(), message(), onscreen
Purpose
Learn how to validate and display the Half-Width katakana character range by converting the characters into Unicode. To explain this, we’ll walk you through the following steps.
- Delete the unnecessary elements on the SAP screen using the del command
- Add an input field to enter data
- AAdd a pushbutton to call a function
- Add functions to validate the Half-Width katakana characters’ range
- Define a function to display the Half-Width katakana characters range
//Create this file inside your script folder for customizing the SAP Easy Access screen: SAPLSMTR_NAVIGATION.E0100.sjs
//Now, let's start adding the Liquid UI script to the above file and save it.
- Delete an ActiveXcontainer and also the unnecessary toolbar elements on the SAP Easy Access screen using the del command, as shown below.
//Delete all existing pushbuttons on toolbar del("P[User menu]");
del("P[SAP menu]");
del("P[SAP Business Workplace]");
del("P[Other menu]");
del("P[Add to Favorites]");
del("P[Delete Favorites]");
del("P[Change Favorites]");
del("P[Move Favorites down]");
del("P[Move Favorites up]");
del("P[Create role]");
del("P[Assign users]");
del("P[Documentation]"); //Delete an Activex image container on the screen
del("X[IMAGE_CONTAINER]");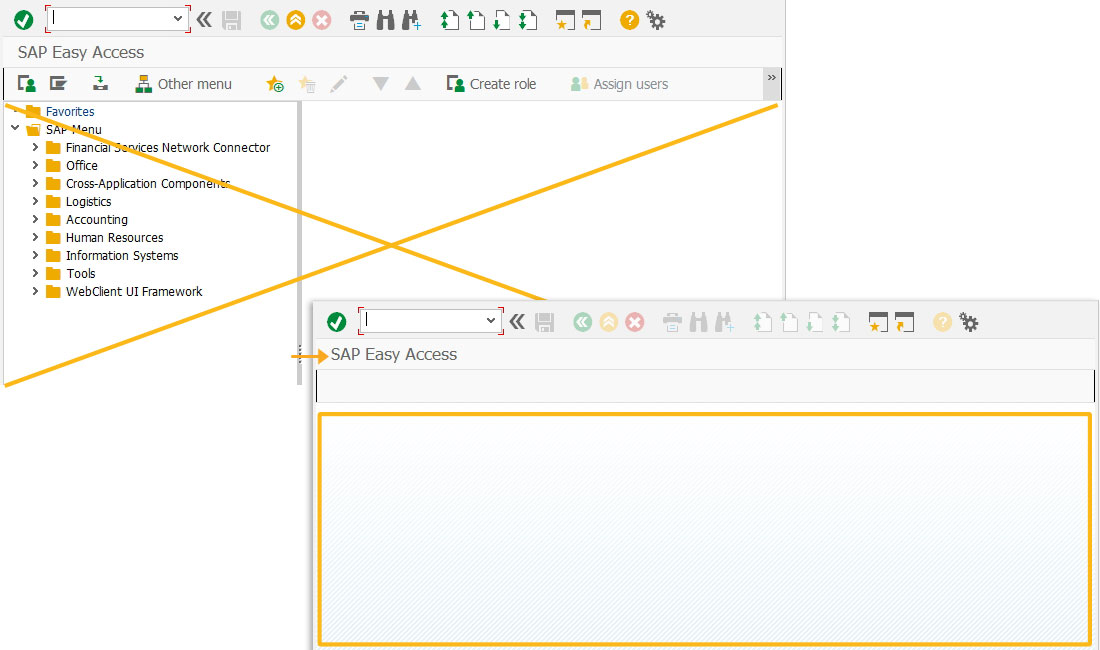
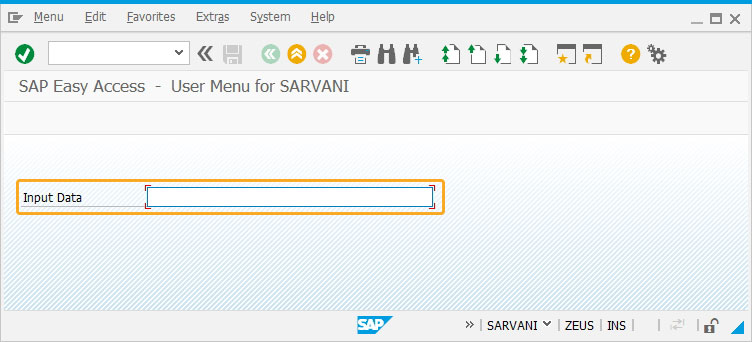
- Add an input field with the label Input Data to enter the katakana characters in it to convert the characters entered to Unicode for validating and displaying Half-Width katakana characters range.
//Creates an input field to enter the katakana characters inputfield([2,2], "Input Data", [2,20],{"name":"z_input", "size":40});
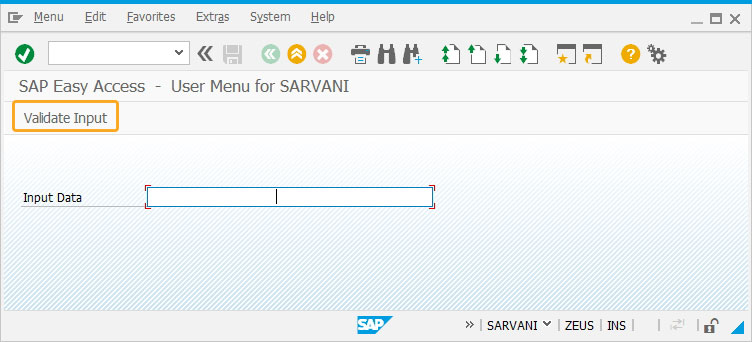
- Add a pushbutton with the label name Validate Input to call the process validateHalfWidthKatakana on click.
//Creates a pushbutton to execute a process validateHalfWidthKatakana on click. pushbutton([TOOLBAR],"Validate Input", "?", {"process":validateHalfWidthKatakana});
- Add a function to validate the converted Unicode result.
//Function to validate the converted unicode result
function validateHalfWidthKatakana(){ onscreen "*" var splited_ary = getSplitedTextAry(z_input); //Logic to split the input data into an array by actual characters var regular_char_counter = 0; var half_width_char_counter = 0; var full_width_char_counter = 0; var other_char_counter = 0; var cur_unicode = ""; //Logic to calculate how many Half-Width Katakana/regular character/number/syntax in the input data for(var k=0; k<splited_ary.length; k++){
if(splited_ary[k].length > 1){
cur_unicode = getUnicode(splited_ary[k]); //Logic to get Unicode for each character if((cur_unicode >= "3000" && cur_unicode <= "30ff") || //Punctuation, Hiragana, Katakana (cur_unicode >= "FF00" && cur_unicode <= "FF9F") || //Full-width Roman, Half-width Katakana (cur_unicode >= "4E00" && cur_unicode <= "9FAF") || //CJK (Common & Uncommon) (cur_unicode >= "3400" && cur_unicode <= "4DBF")) {
//CJK Ext. A (Rare) if(cur_unicode >= "FF61" && cur_unicode <= "FF9F"){ //It's a Half width katakana (Hankaku) half_width_char_counter++; }
else { //It's either Punctuation, Hiragana, Katakana, Full-width Roman, CJK, or CJK Ext. A full_width_char_counter++; } } else { other_char_counter++; //Unhandled characters } } else { regular_char_counter++; //It's regular character/number/syntax } } println("=====>> Half-Width count: "+half_width_char_counter); println("=====>> Full-Width count: "+full_width_char_counter); message("S:Input Data contain " + half_width_char_counter + " Half-Width Katakana"); enter("?"); } - Add a function to return an array with split text.
//Function to return an array with splitted text function getSplitedTextAry(str){ var result_ary = []; var ref_str = str; var converted_str = encodeURI(str); //Converted the string becomes encoded result var converted_str_ary = []; var ref_str_ary = []; //Loop until the converted string becomes nothing while(converted_str.length > 0) { //If Unicode character is found in the string if(converted_str.indexOf("%") > -1){ //If Unicode character is not from the first character if(converted_str.indexOf("%") != 0){ converted_str_ary.push(converted_str.slice(0,converted_str.indexOf("%"))); ref_str_ary.push(ref_str.slice(0,converted_str.indexOf("%"))); ref_str = ref_str.slice(converted_str.indexOf("%")); converted_str = converted_str.slice(converted_str.indexOf("%")); } //When Unicode character is from the first character else { converted_str_ary.push(converted_str.slice(0,18)); //Every actual character are 18 char long after encoded ref_str_ary.push(ref_str.slice(0,3)); //Every actual character are 3 char long before encoded converted_str = converted_str.slice(18); //Subtract the string ref_str = ref_str.slice(3); //Subtract the string } } //When Unicode character is not found in the string else { converted_str_ary.push(converted_str); //Push the rest of the string ref_str_ary.push(ref_str); //Push the rest of the string converted_str = ""; //Clear string } } //Reform the return string for(var k=0; k<converted_str_ary.length; k++){ if(converted_str_ary[k].indexOf("%") < 0){ //If it's a regular character/string for(var j=0; j<ref_str_ary[k].length; j++){ //Push individual characters into the array result_ary.push(ref_str_ary[k].charAt(j)); } } else { //If it's a multi-byte character result_ary.push(ref_str_ary[k]); //Push entire multi-byte character into the array } } return result_ary; }

Note: This logic is required to recognize the individual actual character in the string. Here, we only consider the 3-byte characters for UTF-8 encoding.
- Add a function to convert a multi-byte character to its Unicode value
//Function to return Unicode in string function getUnicode(str){ var result_ary = []; //Logic to get the actual byte value for each unencoded character for(var k=0; k<str.length; k++){ println("===>>"+str.charCodeAt(k).toString(2).substring(24,32)+"<=="); result_ary.push(str.charCodeAt(k).toString(2).substring(24,32)); } //Logic to form multi-byte data become 16-bit hex value switch(result_ary.length){ case 1: // U+00000000 – U+0000007F 0xxxxxxx var ucode = ""; break; case 2: // U+00000080 – U+000007FF 110xxxxx 10xxxxxx var ucode = ""; break; case 3: //U+00000800 – U+0000FFFF 1110xxxx 10xxxxxx 10xxxxxx var c1 = parseInt(result_ary[0],2); var c2 = parseInt(result_ary[1],2); var c3 = parseInt(result_ary[2],2); var b1 = (c1 << 4) | ((c2 >> 2) & 0x0F); var b2 = ((c2 & 0x03) << 6) | (c3 & 0x3F); var ucode = ((b1 & 0x00FF) << 8) | b2; break; case 4: // U+00010000 – U+001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx var ucode = ""; break; case 5: // U+00200000 – U+03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxx var ucode = ""; break; case 6: // U+04000000 – U+7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxx var ucode = ""; break; } println("===>>Unicode="+ucode.toString(16).toUpperCase()+"<=="); //Return Unicode value in hex return ucode.toString(16).toUpperCase(); }
Note: Unicode conversion should include 6 different cases. Here, we only consider the 3-byte characters for UTF-8 encoding.
SAP Process
- Refresh the SAP screen and enter different characters in the Input Data input field. Now, click the Validate Input pushbutton to validate the Half-Width katakana character range, and displays the output on the Status bar, as shown below.
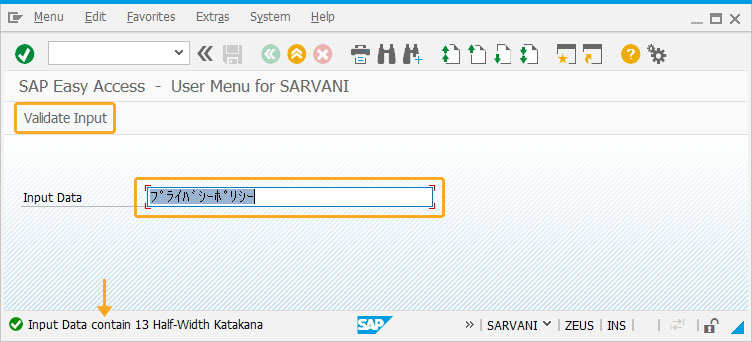
- Enter the different type of Half-Width katakana characters in the input field and click Validate Input. The Half-Width character range is displayed at the status bar as shown below.
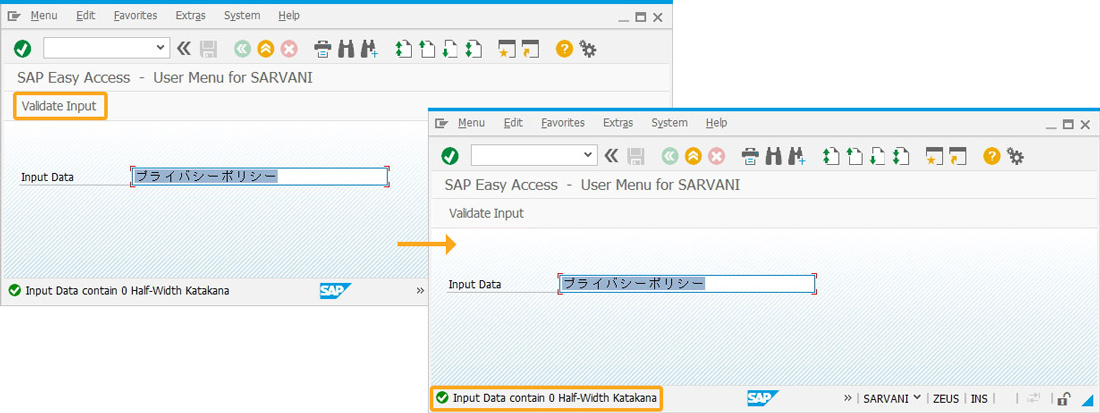
- If entered data doesn’t contain any Half-Width katakana characters, it displays “Input Data contains 0 Half-Width katakana” on the status bar, as shown below.
Next Steps

Learn how to validate time format entered in an input field.
10 min.
This article is part of the Take a deep dive into the input field and pushbutton tutorial.
This article is also a part of the Javascript functions tutorial.



